Da die beiden vorangehenden Iteration aus inhaltlicher Sicht keine zufriedenstellenden Ergebnisse ermitteln konnten, wird erneut eine Iteration der Clusteranalyse durchgefuhrt.
Auswahl der Variablen
In dieser Iteration werden erneut vier Variablen entfernt. Die Variablen wurden erneut sukzessiv betrachtet und auf hinsichtlich ihrer Relevanz verglichen mit den restlichen Variablen evaluiert. Dementsprechend wurde der Variablensatz dieses Mal um die Kennzeichen BAKERY, MOVIE THEATER, NIGHT CLUB und PET STORE gekurzt, sodass nur noch die Variablen aus Abbildung 33 in dieser Iteration betrachtet werden. Auch hier war es schwierig, sich fur diese Variablen zu entscheiden, da allesamt unter dem Annahmensystem aus vorangehendem Kapitel und unter Beachtung der aufgestellten Kriterien als relevant einzuschatzen waren. Demnach bleiben nur die wichtigsten Variablen ubrig, namlich die eindeutigen Konkurrenten in Form von Convenience Stores, Warenhausern, Tankstellen und Supermarkten. Diese Konkurrenten weisen die grote Schnittmenge mit dem Sortiment eines Supermarkts auf. Bezuglich nachfragebeein ussender ortlicher Gegebenheiten bleiben nur der Flughafen und die Bahnstation ubrig, die beide einen bereits in Abschnitt 3.5 erlauterten Ein uss auf die Zahlungsbereitschaft besitzen.

Durchfuhrung der Clusteranalyse
Zur Durchfuhrung der Clusteranalyse werden analog zur Herangehensweise aus derersten und zweiten Iteration neue Zwischentabellen definiert und mit den entsprechendenDaten befullt, da sich die Struktur aufgrund der Ausklammerung einiger Variablenandert. Daraufhin kann die Analyse mit unveranderten Parametern zur ersten Iterationdurchgefuhrt werden.
Prufung der Modellanpassung
Die Modellanpassung ist mit einem Slight Silhouette-Wert von 0.6643 fur dieseParameterkombination gut.
Beschreibung und inhaltliche Interpretation
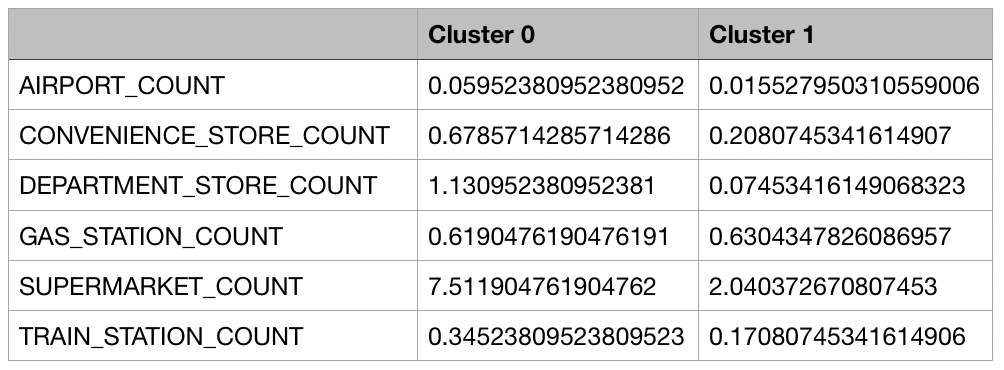
Erneut stellt sich eine 2-Cluster-Losung als die beste Losung heraus. Die Attributsauspragungen der Clusterzentren sind in Abbildung 34 zu sehen, demnach fuhrt dieseIteration zur selben Interpretation in eine Trennung von Filialen mit vielen Lokalitatenund wenigen Lokalitaten:
Cluster 0: Filialen mit einer hohen Anzahl an Konkurrenten und nachfragebeeinussenderPoints-of-Interest im unmittelbaren Umkreis.
Cluster 1: Filialen mit einer niedrigen Anzahl an Konkurrenten und nachfragebeein-ussender Points-of-Interest im unmittelbaren Umkreis.
Werden die Clusterzentren mit den Clusterzentren der ersten und zweiten Iterationverglichen, so lasst sich hier erneut eine enorme Ahnlichkeit feststellen. DieAttributsauspragungen weichen zwar leicht von beiden vorangehenden Losungen ab,allerdings in nur kleinem Ausma, sodass auch hier eine sehr ahnliche Zuordnung derElemente angenommen werden kann und dass die Reduktion auf einen minimalen Satzan Variablen die Clusterlosung kaum verandert hat. Einzig der Zahler fur Tankstellenware als Unterschied anzumerken, da in dieser Losung beide Clusterzentren einen Wertum 0.6 aufweisen, wobei die Werte in den vorangehenden Iterationen unterschiedlicheAuspragungen aufweisen konnten.
Inhaltliche Validit atspr ufung
Auch nach einer weitere Ausklammerung potentiell nicht relevanter Variablen ergibt sich keine Ver anderung der Clusterzentren. Da ein weiteres Ausklammern zus atzlicher Variablen kaum noch Variablen zur Clusteranalyse ubrig lassen w urde, und sich auch nur bei Betrachtung der relevantesten Variablen die 2-Cluster-L osung als beste L osung herausstellt, ist dies entweder die wahre Clusterstruktur, oder es sind andere Manahmen notwendig, um die Analyse zu einer granulareren Clusterstruktur zu f uhren.
Stabilitatstests
Bei der Nutzung anderer Distanzmae ergeben sich teils 3-Cluster-L osungen mit niedrigerer Silhouette, als in der in Abbildung 35 gezeigten Tabelle bez uglich der Slight Silhouette-Werte unterschiedlicher Parameterkombinationen. Nach mehrmaliger
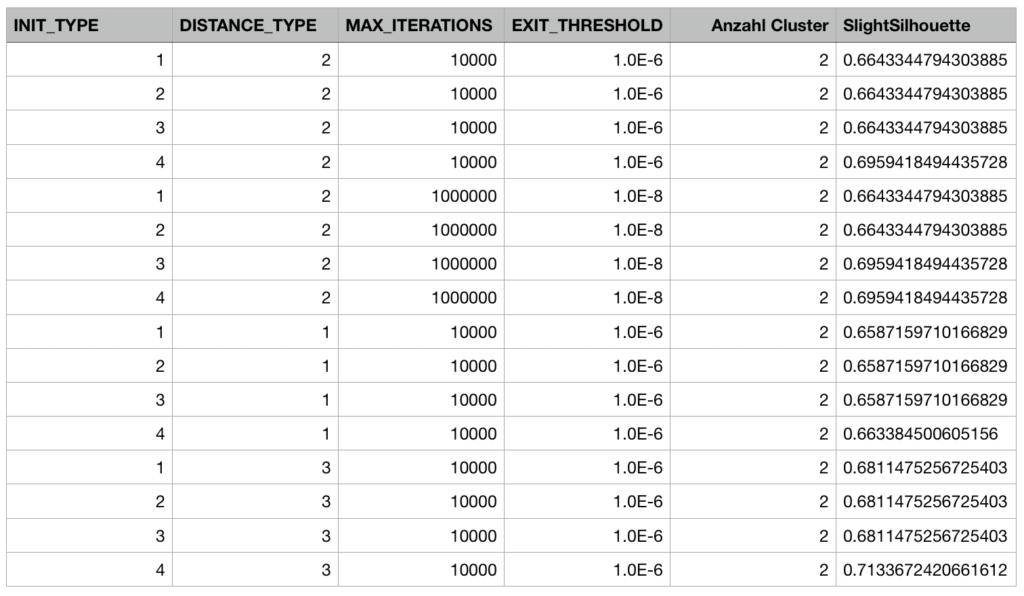
Abb. 35: Verschiedene Parameterkombinationen fur die dritte Iteration der Clusteranalyse und die daraus resultierenden Werte der Slight Silhouette der jeweiligen Clusterlosung
Durchfuhrung mit exakt derselben Parameterkombination stellt sich jedoch wieder die 2-Cluster-Losung als dominant heraus. Dies kann dadurch erklart werden, dass die Startpunkte in manchen Initialisierungsmethoden zufallig gewahlt werden und die anderen Distanzmae im Vergleich zur euklidischen Distanz bei Nutzung des k-Means-Algorithmus langsamer zur Losung konvergieren (vgl. [Singh et al., 2013]), womit die Iterationen abgebrochen wurden, bevor das eigentliche Optimum, namlich die 2-Cluster-Losung, gefunden wurde. Teilweise werden auch fur die 2-Cluster-Losung bei bestimmten Parameterkombinationen leicht unterschiedliche Slight Silhouetten gefunden, die fur leicht unterschiedliche Zuordnungen zu den Clustern stehen. Dies ist insbesondere bei den beiden Initialisierungsmethoden der Fall, bei denen die Zuordnung der Startpunkte zufallig stattfindet (INIT TYPE 2 und 3). Diese wiesen in wenigen Fallen den Wert der Slight Silhouette auf, der mit der vierten Initialisierungsmethode ermittelt wurde. Allerdings wurden in jedem Fall, auer explizit anders vermerkt, mehrere Durchfuhrungen der Clusteranalyse mit jedem Parametersatz vorgenommen, wobei sich meist klar eine Slight Silhouette herausgestellt hat, die sich im Groteil der Falle ergab und hier aufgefuhrt ist.
Formale Gultigkeitsprufung
Der tatsachliche Silhouettenkoeffizient der Losung der ursprunglichen Parameterkombination liegt bei einem Wert von 0.5667, der annehmbar ist, womit auch diese Losung aus formaler Sicht eine gute Losung darstellt.
Recent Comments