Big-Data-Analysen
Technologien zur Datenerfassung und Verarbeitung wurden bereits im 2. Kapitel vorgestellt. Nun soll die Kernaufgabe von Big-Data, die Gewinnung von Erkenntnissen anhand der gespeicherten Daten, thematisiert werden.
Big-Data-Analysen helfen Unternehmen dabei, sachkundigere Entscheidungen zu treffen. (Pyne et al. 2016, S. 15) Bei den Analysen kann zwischen drei Analyseschritten (vgl. Abbildung 7) unterschiedenen werden, die aufeinander aufbauen.
Nachfolgend werden die Analyseschritte differenziert und einzelne Techniken und Algorithmen vorgestellt, die auf Big-Data angewendet werden können, um das Vorgehen bei den Analysen zu erläutern. Dabei liegt der Fokus nicht darauf, einzelne mathematische Formeln oder Algorithmen herzuleiten und im Detail zu beschreiben, sondern dessen Aufgaben und Möglichkeiten zu verdeutlichen.
Deskriptive Analysen
Deskriptive (beschreibende) Analysen beschäftigen sich mit historischen Daten zur Erkennung von Mustern wie beispielsweise Abweichungen in Betriebskosten, Absätze von verschiedenen Produkten oder Kaufpräferenzen von Kunden. Diese Form der Analyse wird typischerweise als erster Schritt durchgeführt, da sie Fragen darüber beantwortet, was passiert ist und was in der Gegenwart passiert. (Pyne et al. 2016, S. 15; Delen und Demirkan 2013, S. 361) Bei deskriptiven Analysen kann zwischen OLAP (Online Analytical Processing) und Statistik als Hauptbereiche unterschieden werden. (Sharda et al. 2017, S. 75)
OLAP, das bereits in 2.4 eingeführt wurde, ermöglicht die Analyse, Charakterisierung und Zusammenfassung strukturierter Daten, die in Data-Warehouses oder Data-Marts gespeichert werden. (Sharda et al. 2017, S. 75) Datenanalysten können mit Hilfe von OLAP durch die Datenbasis navigieren und die Daten je nach Anwendungszweck aggregieren oder disaggregieren (drill down/up). (Sharda et al. 2017, S. 158–159) OLAP basiert auf dem sogenannten Cube (Würfel) Konzept, welches eine multidimensionale Datenstruktur darstellt und schnelle Analysen ermöglicht. So kann zu bestimmten Teilmengen von Daten navigiert werden. Ein dreidimensionaler Datenwürfel kann beispielsweise die Dimensionen Zeit, Produkt und geographische Lage besitzen. Ein Datenanalyst kann dann den Absatz eines Produkts in einer bestimmten Region identifizieren. (Sharda et al. 2017, S. 159–160; Bitkom 2014, S. 70)
Die Statistik unterstützt deskriptive Analysen mit mathematischen Techniken, um Daten zu charakterisieren und interpretieren. Auf der abstraktesten Ebene kann zwischen de skriptiver und induktiver Statistik unterschieden werden. Deskriptive Statistik beschreibt grundlegende Eigenschaften der Daten, oft basierend auf einzelnen Variablen. Mit Hilfe von Formeln und numerischer Aggregation werden die Daten so zusammengefasst, dass aussagekräftige und leicht verständliche Muster auftreten. Im Rahmen von Datenanalysen spielt die deskriptive Statistik eine zentrale Rolle, da sie dabei hilft, Daten zu erklären und in aggregierter Form aufzubereiten. Sie unterstützt so einerseits Entscheidungsprozesse im Unternehmen und andererseits hilft sie dabei, Daten für anspruchsvollere Analysen zu charakterisieren und validieren. Deskriptive Statistik erlaubt es, die Streuung von Daten zu erkennen, zum Beispiel besonders hohe oder niedrige Werte (Ausreißer). Lageparameter sind die mathematische Methode, um die Lage von Variablen zu bestimmen. Dazu zählen beispielsweise das arithmetische Mittel und der Median. Mathematische Methoden zur Feststellung von Streuungen beschreiben den Grad der Veränderung von Variablen. Dazu gehört zum Beispiel die Varianz, die die Abweichung aller Datenpunkte einer Datenmenge vom Mittelwert berechnet. Je größer die Varianz, desto mehr sind die Datenpunkte vom Mittelwert verteilt. (Sharda et al. 2017, S. 75–76)
Bei der induktiven Statistik ist die Regression, im speziellen die lineare Regression eine weit verbreitete Analysetechnik. Sie wird verwendet, um die Abhängigkeit einer Variable (Output-Variable) zu einer oder mehreren erklärenden Variablen (Input-Variablen) zu modellieren. Sobald die Beziehung identifiziert wurde, kann sie als formale, lineare oder additive Funktion dargestellt werden. Das Ziel der Regression ist es, Beziehungen der Charakteristika der realen Welt zu erfassen und diese als mathematisches Modell zu repräsentieren. Regression kann für zwei Aufgaben eingesetzt werden: Erforschung von potentiellen Beziehungen zwischen Variablen zum Testen von Hypothesen, wie es in der deskriptiven Analyse genutzt wird und für Prognosen, die Bestandteil der prädiktiven Analyse sind.
Die Informationen, die durch deskriptive Analysen gewonnen wurden, werden beispielsweise in der Form von Reports (Berichten) an die entsprechenden Entscheidungsträger übermittelt. Sharda et al. fassen Reports als jegliche Form der Kommunikation (schriftlich oder mündlich) zusammen, dessen Aufgabe es ist, die zu übermittelnden Informationen in verständlicher Weise an jede betroffene Person und zu jedem benötigten Zeitpunkt zu übermitteln. (Sharda et al. 2017, S. 98) Soltanpoor und Sellis beschreiben diese Phase als die Datenzusammenfassung, weil die folgenden Analyseschritte unter anderem auf den Informationen der deskriptiven Analysen aufbauen. (Soltanpoor und Sellis 2016, S. 247)
Prädiktive Analysen
Prädiktive (voraussagende) Analysen dienen der Vorhersage von zukünftigen Trends oder Ereignissen. Während deskriptive Analysen also die Aufgabe haben, die Vergangenheit besser zu verstehen, sollen prädiktive Analysen dabei helfen, Entscheidungen für die Zukunft zu treffen. (Pyne et al. 2016, S. 16)
Das sogenannte Data-Mining spielt bei der prädiktiven Analyse eine zentrale Rolle. Der Begriff beschreibt das Entdecken von Wissen in großen Datenmengen. Aus technischer Sicht werden statistische und mathematische Methoden verwendet, um nützliche Informationen und anschließend Wissen (Muster) aus den Daten zu extrahieren. (Sharda et al. 2017, S. 196)
Je nach Art und Weise, in der die Muster aus den Daten extrahiert werden, kann außerdem zwischen überwachtem und unüberwachtem Lernen unterschieden werden. (Sharda et al. 2017, S. 200–201) Machine Learning, ein Teilgebiet der künstlichen Intelligenz, macht sich diese Formen des Lernens zunutze, um verschiedene Aufgaben durchzuführen. Diese Aufgaben müssen nicht zwangsläufig zu Prognosezwecken verwendet werden, im Rahmen dieser Arbeit liegt darauf allerdings der Fokus beim Machine Learning. Beim überwachten Lernen erhält der Computer Trainingsdaten mit Input und Output, anhand dessen dieser Muster entwickeln soll, um zukünftige Probleme zu lösen. Unüberwachtes Lernen beinhaltet Daten ohne Lösungen und der Computer muss eigenständig Lösungen finden. (Louridas und Ebert 2016, S. 111–113) Machine Learning wird deshalb in der Big-Data Umgebung eingesetzt, weil Datenanalysten mit hypothesengetriebenen Analysen nicht alleine die Komplexität und den Umfang von Big-Data bewältigen können. (Davenport 2013, S. 15) Machine Learning ermöglicht es durch seine Algorithmen, intelligente Applikationen zu erstellen, die selbstständig Muster erkennen und somit die Datenanalyse unterstützen. (Prajapati 2013, S. 149)
Im Folgenden werden die Teilgebiete des Data-Mining, die Bestand präskriptiver Analysen sind, vorgestellt (Sharda et al. 2017, S. 201) :
• Prognose
Unter Prognosen versteht man das Vorhersagen über die Zukunft. Es unterscheidet sich vom einfachen raten, indem Erfahrungen, Optionen und andere relevante Informationen mit in Betracht gezogen werden. (Sharda et al. 2017, S. 200)
Klassifikation ist laut Sharda et al. die am weitesten verbreitete Data-Mining Tätigkeit. Dessen Aufgabe besteht darin, historische Daten zu analysieren und daraus automatisch ein Modell zu generieren, welches Prognosen über zukünftiges Verhalten offenbart. (Sharda et al. 2017, S. 200) Klassifikationsmethoden sind Teil des überwachten Lernens. Die Algorithmen erhalten Trainingsdaten, die bereits klassifiziert sind, um die Wahrscheinlichkeiten zu lernen, dass diese Beobachtungen zur Klassifizierung zukünftiger, nicht zugeordneter Beobachtungen beitragen. Beispielsweise können E-Mail Provider Klassifikation zur Entscheidung verwenden, ob eingehende E-Mails Spam sind. (EMC Education Services. 2015, S. 192) Verwendete Algorithmen sind unter anderem Entscheidungsbäume (Decision Trees) und künstliche Neuronale Netzwerke. Entscheidungsbäume entwickeln ein geeignetes Modell zur Prognose von Zielvariablen, basierend auf Input Variablen. Künstliche Neuronale Netzwerke sind Modelle, dessen Architektur der von tierischen Gehirnen nachempfunden ist. Neuronen sind Zellen, die chemische oder elektrische Signale verarbeiten und weiterleiten. Das Netzwerk basiert dabei auf einfachen Formen von Input und Output. In der Biologie können Neuronen tausende verschiedene Inputs verarbeiten. Künstliche neuronale Netzwerke können ebenfalls verschiedene Inputs verarbeiten und weisen auch bei großen Datenmengen und einer hohen Geschwindigkeit Erfolg auf, weshalb sie vor allem bei Echtzeitanalysen verwendet werden. (Bell 2014, S. 91–92)
Eine weitere Methode sind Regressionsanalysen. Wie bereits bei der deskriptiven Analyse angemerkt kann diese auch für Prognosezwecke eingesetzt werden. Da bei der Regression die Abhängigkeiten von Variablen erforscht werden, können darauf basierend Prognosen für zukünftige Entwicklungen erstellt werden. (EMC Education Services. 2015, S. 162)
Bei der Zeitreihenanalyse wird die zugrundeliegende Struktur von Überwachungen in einem bestimmten Zeitraum modelliert. Ziel der Zeitreihenanalyse ist einerseits die Identifikation und Modellierung der Struktur der Zeitreihe und andererseits die Prognose zukünftiger Werte der Zeitreihe. Bei der Box-Jenkins Methode besteht die Zeitreihe aus Werten mit dem gleichen Abstand zueinander. Das können beispielsweise monatliche Arbeitslosenquoten oder tägliche Webseiten-Besuche sein. Die drei Schritte dieser Methode lauten Bestimmung der Daten und Auswahl eines Modells, sowie Identifikation von Trends oder saisonalen Abhängigkeiten der Zeitreihe, Abschätzung der Modellparameter und zuletzt Beurteilung des Modells. Falls nötig wird der Prozess dann von vorne begonnen. (EMC Education Services. 2015, S. 235)
• Assoziationsanalyse
Die Assoziationsanalyse ist ein weit verbreitetes Data-Mining-Verfahren zur Aufdeckung von Beziehungen zwischen Variablen in großen Datenbeständen. Ein Anwendungsgebiet ist im speziellen die Analyse der Warenkorbdaten. Um Prognosen über zukünftige Einkäufe anzustellen, werden die PoS-Daten der vergangenen Einkäufe (Transaktionen) hingehend des Inhalts der Warenkörbe (Items) analysiert. Bei der Bondatenanalyse sind die Variablen verschiedene Einkaufsvorgänge und es werden die Beziehungen zwischen diesen und den gekauften Produkten hergestellt. Ein verwendeter Algorithmus ist Apriori, der Datensätze einzeln durchläuft und Korrelationen zwischen Transaktionen und Items aufdeckt. (Bell 2014, S. 117–124)
• Segmentierung
Segmentierung kann durch Clusteranalysen und Ausreißeranalysen erfolgen. (Sharda et al. 2017, S. 201) Bei der Clusterananlyse werden im Kontext des Machine Learning Objekte automatisch in verschiedene Cluster (Gruppen) einsortiert. Es handelt sich um ein unüberwachtes Verfahren. Das bedeutet in diesem Fall, dass Datenanalysten die einzelnen Cluster nicht im Vorhinein benennen und Eigenschaften festlegen. Stattdessen beschreibt die Struktur der Objekte selbst, wie diese gruppiert werden sollen. Ein verwendeter Algorithmus ist der k-Means-Algorithmus. Vereinfacht gesagt identifiziert dieser für einen festgelegten Wert k, eine Anzahl von k Clustern ähnlicher Objekte. (EMC Education Services. 2015, S. 118–119)
Der k-Means-Algorithmus kann außerdem Ausreißerobjekte ermitteln, die besonders weit von den identifizierten Clusterzentren entfernt liegen und somit Ausnahmen in der Datenmenge bilden. Das kann bei der Bildverarbeitung hilfreich sein, um beispielsweise bei Sicherheitsvideos Veränderungen zwischen einzelnen Frames festzustellen. (EMC Education Services. 2015, S. 119)
Die Unterscheidung zwischen deskriptiver und prädiktiver Analyse liegt im Zeitraum, der betrachtet wird, also deskriptive Analysen in der Vergangenheit und Gegenwart und prediktive Analysen in der Zukunft, und in der daraus resultierenden steigenden Komplexität der benötigten Werkzeuge und Algorithmen, denn es werden nicht nur Tatsachen wie bei der deskriptiven Analyse wiedergegeben (Was ist passiert?), sondern es werden Prognosen angestellt, was passieren wird und auch warum es passieren wird. (Sharda et al. 2017, S. 131)
Präskriptive Analysen
Während deskriptive und prädiktive die Vergangenheit beschreiben bzw. die Zukunft vorhersagen sollen, besteht der nächste Schritt im Entscheidungsprozess in der Frage, wie Entscheidungen auf Grundlage der Analysen umgesetzt werden können. Präskriptive (vorschreibende) Analysen sollen dabei helfen, die Auswirkungen verschiedener, möglicher Entscheidungen abzuwägen und so Fachleute bei der Wahl der Entscheidung zu unterstützen. Trotz der scheinbar nützlichen Unterstützung dieser Analysen verwenden laut Gartner im Jahr 2012 nur 3% der Unternehmen präskriptive Analysemethoden zur Entscheidungsunterstützung (Drew 2012). Ein mögliches Anwendungsgebiet ist der Gesundheitssektor. Präskriptive Analysen können Diagnosen und Behandlungen auf Basis der medizinischen Historie des Patienten vorschlagen, um Entscheidungen von Ärzten zu unterstützen. (Pyne et al. 2016, S. 17)
Methoden der Präskriptiven Analyse umfasst unter anderem die Entwicklung mathematischer Modelle zur Entscheidungsmodellierung sowie Simulationen, um verschiedene mögliche Ergebnisse der prädiktiven Analysen abzuwägen und Optimierungsmaßnahmen. (Sharda et al. 2017, S. 320; Soltanpoor und Sellis 2016, S. 247)
Mathematische Modelle bestehen in der Regel aus vier Komponenten. Ergebnisvariablen beschreiben die Effektivität eines Systems und beschreiben, wie gut die Ziele errreicht werden. Bei Finanzinvestitionen können das beispielsweise der gesamte Profit oder der Gewinn pro Aktie sein. Entscheidungsvariablen beschreiben die verschiedenen Handlungsoptionen. Der Entscheidungsträger kontrolliert diese Variablen. Beim genannten Beispiel können das Investitionsalternativen sein. Die nächste Komponente sind nicht kontrollierbare Variablen oder Parameter, die die Ergebnisvariable beeinflussen, aber nicht verändert werden können. Im Beispiel kann das die Inflationsrate sein. Die letzte Komponente sind Zwischenergebnisvariablen. Diese stellen Zwischenergebnisse in mathematischen Modellen dar, die Einfluss auf die Ergebnis- oder Entscheidungsvariablen haben. Der Modellierungsprozess besteht aus der Identifizierung der Variablen und Beziehungen zwischen ihnen. Das Lösen des Modells bestimmt die Werte der Ergebnisvariablen. (Sharda et al. 2017, S. 328–329)
Simulationen modellieren das Verhalten komplexer Systeme und werden zur Prognose und Planung von verschiedenen möglichen Szenarien verwendet. Monte Carlo Simulationen sind beispielsweise eine Sammlung von Algorithmen, die auf wiederholten Stichprobenanalysen basieren. Dazu können tausende Simulationen mit verschiedenen Annahmen durchgeführt werden. Als Ergebnis erhält man ein Histogramm, das die Häufigkeitsverteilung der verschiedenen Ergebnisse darstellt. (Manyika et al. 2011, S. 29)
Optimierung ist die Bezeichnung für ein ganzes Portfolio numerischer Techniken zur Überarbeitung von Systemen und Prozessen, um dessen Performanz zu steigern. Dazu werden objektive Maßnahmen (z.B. Kosten, Geschwindigkeit, Zuverlässigkeit) zugrunde gelegt. Eine Optimierungstechnik sind genetische Algorithmen, die von der biologischen Funktionsweise von Genen inspiriert sind. Genetische Algorithmen sind ein Bereich der evolutionären Algorithmen, deren Funktionen von der Evolution abgeleitet sind. (Reeves und Rowe 2004, S. 1–2)
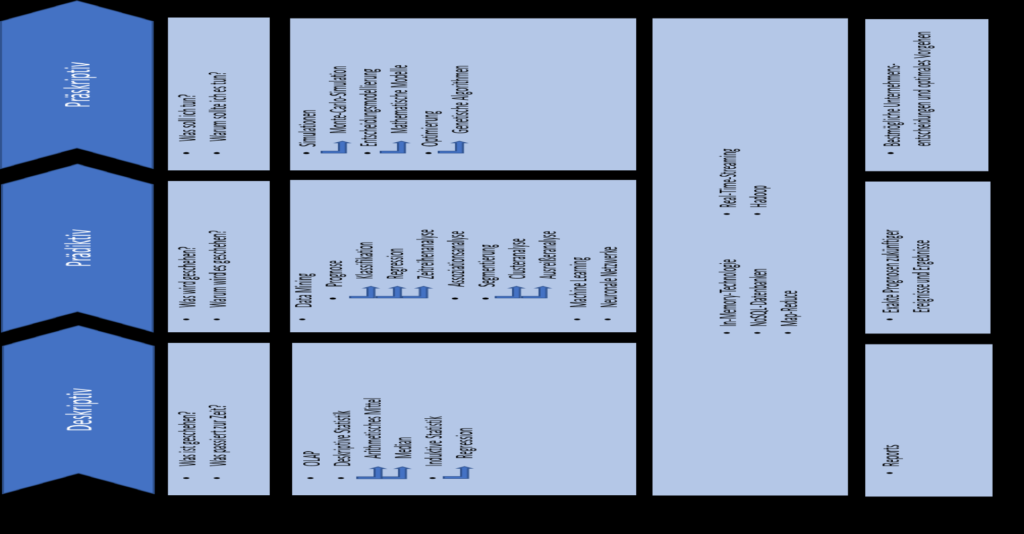
Abbildung 7: Klassifikation und Eigenschaften von Big-Data-Analysen (in Anlehnung an Sharda et al. 2017, S. 131, 201)
Bedeutung von Technologien für Big-Data-Analysen
Im Zusammenhang mit Big-Data-Analysen wird häufig der Begriff Analytik verwendet. Dieser bezeichnet sowohl Prozesse, um Daten zu analysieren, als auch Technologien, die zu dessen Unterstützung verwendet werden. Analysen sind somit ein Teilaspekt der Analytik. (King 2014, S. 39) In diesem Kapitel wird die Bedeutung von Technologien zur Unterstützung von Big-Data-Analysen aufgezeigt und so die gesamte Analytik von Big- Data beschrieben.
Wie Davenport und Dyché beschreiben, bestand der Großteil der Datenanalysen im Unternehmenskontext vor Big-Data aus deskriptiven Analysen. (Davenport und Dyché 2013, S. 26) Haben die Daten nicht das Volumen von Big-Data, können Werkzeuge wie OLAP die Rechenoperationen in wenigen Sekunden durchführen. Mit Big-Data sinkt diese Geschwindigkeit jedoch. In-Memory Datenbanken (vgl. 2.2.2.2) können dabei Abhilfe schaffen, indem die Würfel (Cubes) komplett oder in Teilen im Hauptspeicher abgelegt werden und somit die Berechnungsoperationen beschleunigt werden. Eine weitere Möglichkeit besteht darin ein DWH-System, das auf Hadoop aufbaut, wie beispielsweise Apache Hive, zu verwenden. Hive unterstützt Ad-hoc-Abfragen zwar, die Geschwindigkeit ist jedoch unzureichend. Die relevanten Hadoop-Daten können jedoch auch in einen relationalen OLAP-Cube gebracht werden, um die Daten für Analysen und Berichte bereitzustellen. Dadurch können Antwortzeiten von weniger als 10 Sekunden für 1 Billion Datenzeilen erreicht werden. (Bitkom 2014, S. 70)
Es zeigt sich, dass bei deskriptiven Analysen die zugrundeliegenden mathematischen Formeln und Werkzeuge wie OLAP nicht erst seit Big-Data-Analysen verwendet werden. Trotzdem erfordert die deskriptive Big-Data-Analyse Anpassungen an bestehenden Technologien, um das Datenvolumen handhaben zu können.
Dies trifft auch auf die prädiktiven und präskriptiven Big-Data-Analysen zu. (Manyika et al. 2011, S. 27) Die Algorithmen der Analysen können zu Map-Reduce Algorithmen übersetzt werden, um sie auf Hadoop Clustern ausführen zu können. Das geschieht, indem dessen Datenanalyse Logik auf Map-Reduce angepasst wird, das wiederum über die Hadoop Cluster läuft. (Prajapati 2013, S. 115) Daraufhin können auch Daten unterschiedlicher Strukturen durch Hadoop und Map-Reduce in strukturierte und quantitative Daten transformiert werden, sodass die Big-Data-Analysemethoden auf die Daten angewendet werden können, da die Daten in unstrukturierter Form nicht analysiert werden können (Davenport 2013, S. 17) Das geschieht durch den ELT (Extract, Load, Transform) -Prozess von Hadoop. Die Reihenfolge des Lade- und Transformationsprozesses wird dabei im Gegensatz zum ETL-Prozess vertauscht. Es werden also alle Daten der verschiedenen Quellsysteme extrahiert, bereinigt und gespeichert, egal ob sie für die Auswertung relevant sind oder nicht. Der Transformationsprozess führt die die Umwandlung der unstrukturierten Daten in strukturierte Daten durch. (Schön 2016, S. 309)
Neben der Speicherung und Aufbereitung von Big-Data helfen die Technologien auch bei der Analyse der Daten selbst (Grossmann und Rinderle-Ma 2015, S. 330). So wird die Geschwindigkeit der Analysen (Velocity) durch Real-Time Streaming Frameworks wie Storm erhöht. Das wird durch die In-Memory-Technologie ermöglicht, indem die Daten noch analysiert werden, bevor sie auf einer Festplatte persistent gespeichert werden (Fasel und Meier 2016, S. 134). Es gibt also bei Big-Data-Analysen einerseits die Möglichkeit, diese Batch-orientiert durchzuführen, wie bei den deskriptiven Analysen und OLAP verdeutlicht, oder in Echtzeit-Analysen. Beide Vorgehen können dabei von der In-Memory-Technologie profitieren, um die Geschwindigkeit zu erhöhen. Auch NoSQl-Datenbanken wie Apache HBase können bei Echtzeitanalysen von multistrukturellen Daten (vgl. 2.2.2.1) helfen, wenn Echtzeit Lese- oder Schreibzugriff auf die Daten benötigt wird (Apache HBase 2017).
Des Weiteren werden Machine Learning Algorithmen durch Real-Time Streaming Frameworks wie Storm unterstützt (Apache Storm 2017). Dazu kann beispielsweise die Programmierumgebung Apache Mahout verwendet werden, die es ermöglicht, skalierbare Machine Learning Applikationen für die Hadoop Plattform zu entwickeln.
Die Ausführungen zeigen, dass für die Analyse von Big-Data nicht nur die Analysemethoden und Algorithmen selbst ausreichend für die Entscheidungsunterstützung im Unternehmenskontext ist, sondern auch die Wahl der entsprechenden Technologien. Erst die Big-Data-Technologien ermöglichen die Handhabung der kennzeichnenden Eigenschaften von Big-Data (4V) und unterscheiden somit die Analysen von solchen, die bereits ihren Ursprung in den 50er Jahren hatten und zu Teil auf den gleichen Methoden und Algorithmen wie Big-Data-Analysen basieren (Davenport und Dyché 2013, S. 26). Wie sich zeigt, können mit Hilfe von Frameworks wie Hadoop die verschiedenen Technologien zur Speicherung und Verarbeitung von Big-Data zusammengeführt werden.
Recent Comments